The Latest Buzz
How It Works: Hivemapper’s Map AI

This is Part 2 in a series on how Hivemapper is building decentralized Map AI. In Part 1, we shared our “master plan” and why it’s time for a revolution in how maps are built.
What is a map? At its core, a map is a collection of symbols and images that stand for features of the real world, whether they are handwritten in chalk, printed in a book or digitized in an app.
Those real-world Map Features change all the time. Roads are built. Speed limit signs are changed. Even the natural landscape changes; here in California, coastal cliffs are regularly washed out by storms, making roads such as the iconic Pacific Coast Highway impassable.
Dashcams are the eyes that allow the Hivemapper network to sense those changes. In June for example, a truck fire collapsed an I-95 overpass in Philadelphia and shut down the entire highway. Within days of the highway reopening, several people with Hivemapper dashcams drove by and captured useful information about the new configuration of highway lanes. (As of today, almost a month after the highway reopened, Google Street View shows imagery from before the collapse.)

In the first half of 2023, we opened the eyes of the Hivemapper network by shipping and onboarding thousands upon thousands of dashcams around the world. Our fast-growing community of contributors has already collected 4 million unique kilometers of imagery, or about 6% of the world’s roads. In some pioneering cities, such as Singapore, nearly all the roads have been mapped at least once.
This is an incredible feat that clearly shows the power of decentralized map collection. But as with human cognition, eyes are not enough - you need a brain to interpret what you see.
In the second half of 2023, Hivemapper is focused on increasing the brainpower of its Map AI through tools such as AI Trainers. Since the launch of AI Trainers in April, the community has done millions of bite-sized tasks to help teach the AI what human contributors know.
With their help, the Map AI processing pipeline is now operational, allowing map data customers to consume map data through Hivemapper’s Map Image and Map Features APIs. Every time map data is consumed, the contributors of the map data receive added rewards, balancing supply and demand by rewarding the most useful contributions.
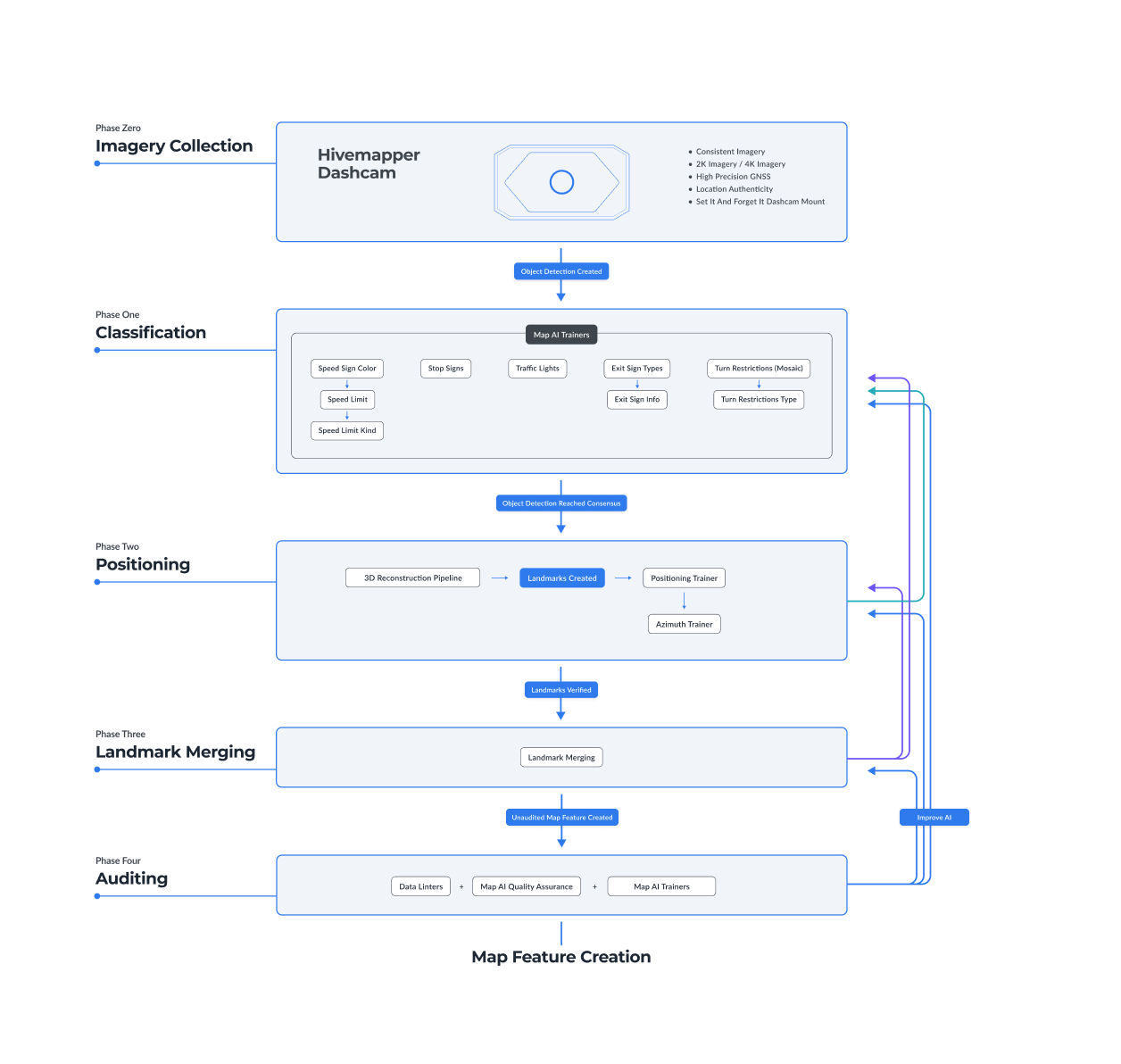
As shown in the diagram above, the pipeline has four phases: Classification, Positioning, Merging and Auditing. Let’s get into the nitty-gritty of how it works.
Phase One: Object Detection and Classification
The first job of Hivemapper’s Map AI is detecting and interpreting objects, like humans can.
A human driver can glance at a speed limit sign for a fraction of a second and instantly understand its meaning: “I can’t drive faster than 55 miles per hour here.” If a human can do that, based on their knowledge of codified rules about the design and meaning of roadway signs, so can the Map AI.
To start the process, human annotators review raw imagery from the Hivemapper network and find examples of Map Features. Hivemapper’s engineers use those examples to train machine learning models that can identify the same objects from raw imagery.
In this example, the colored boxes represent different classes of objects that are being annotated, including street signs, traffic lights and a one-way sign.

These models are powerful, but not perfect. If the dashcam’s view of a real-world object was partially obstructed, at an oblique angle or from a distance, the image may not be clear enough for the ML model to have a high level of confidence.
This is why Hivemapper also relies on human reviewers to confirm the lower-confidence outputs of ML models. Object detections that get the stamp of human approval become additional examples used to train the Map AI. While most reviewers are human, some humans have created their own AI models that they use to contribute to the process. As long as they do a good job, both humans and AI models are acceptable reviewers.
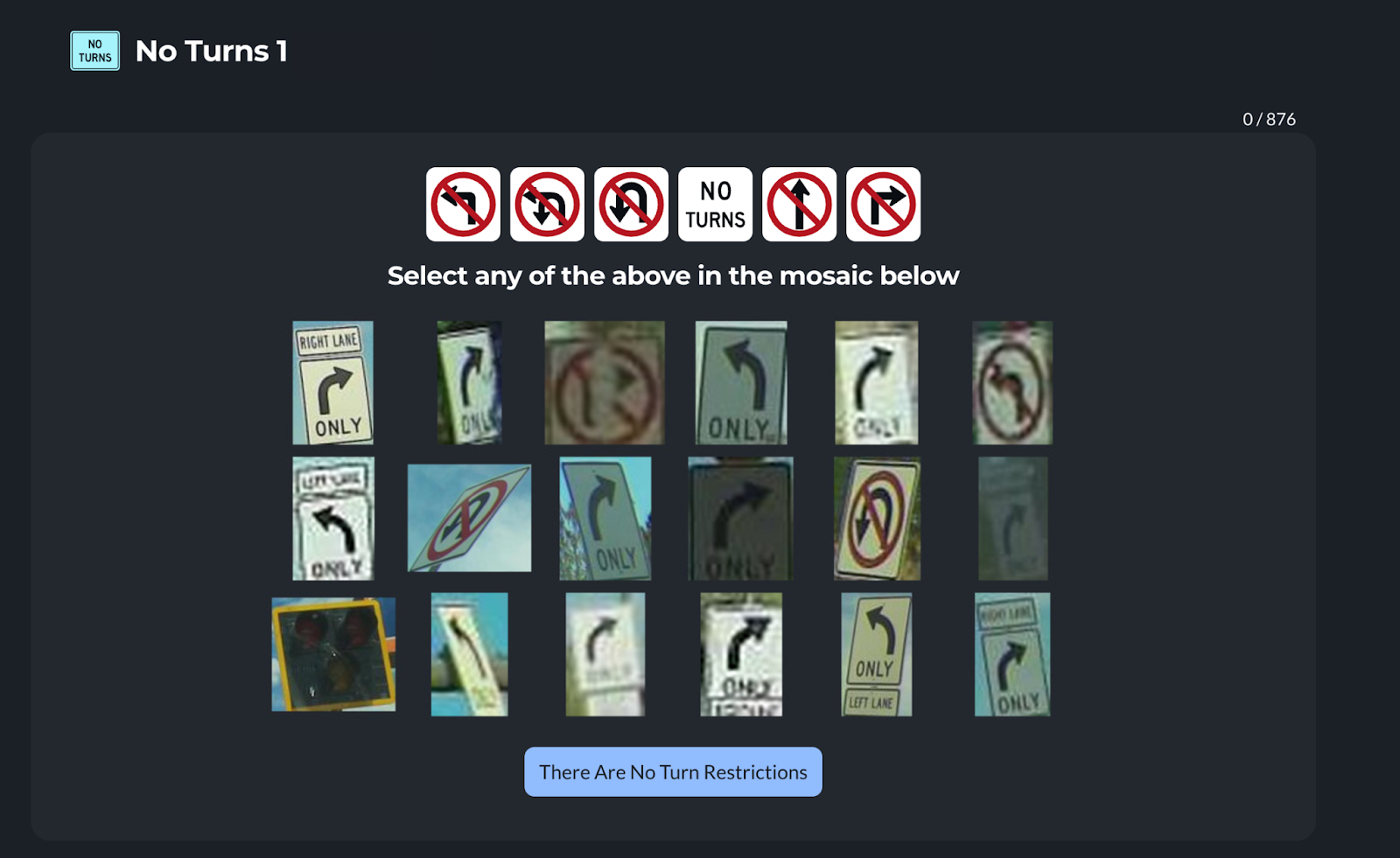
So far, we support five classes of objects for the United States: speed limit signs, stop signs, turn restriction signs, highway exit signs and traffic lights. More classes will be added over time, across all regions of the world. Because of regional differences in signage and roadway infrastructure, different models will be created to reliably generate Map Features around the world.
Phase Two: Positioning
In the next phase, we move from detecting objects to the far more difficult task of positioning them.
Without accurate positioning, you cannot build a useful map. People often ask why Hivemapper developed its own dashcam, and this is probably the most important reason. Anytime a project tries to use smartphone cameras to collect map data, they tend to learn that the positioning is simply not good enough on its own.
We designed the Hivemapper Dashcam and Hivemapper Dashcam S with an extremely reliable and secure GPS/GNSS module, the encrypted U-Blox NEO-M9N, as well as an IMU (Inertial Measurement Unit) sensor. By comparison, smartphone positioning is far less precise and far more prone to spoofing.
Even with purpose-built hardware, GPS/GNSS technology has weaknesses. Most notably, the technology relies on a direct line of sight to satellites, leading to poor positioning in tunnels, hilly terrain and “urban canyons” where the dashcam is surrounded by tall buildings. There are several technologies that can compensate for these deficiencies, such as sensor fusion and real-time kinematics, or RTK. Continuously improving positional accuracy while keeping hardware inexpensive for decentralized collection will always be a core focus for the Hivemapper project.
To correctly position Map Features on Hivemapper’s map, the Map AI relies on more than just raw GPS/IMU data. When a relevant object is detected, Hivemapper uses photogrammetry, image processing and point cloud processing to generate a three-dimensional reconstruction of the scene and place the object in its correct location relative to the dashcam.

In combination with this 3D reconstruction, we use semantic segmentation to filter out objects (cars, sky, etc.) that are not relevant for our use case, thereby improving the positional accuracy of the objects we do care about. Once positioned, we call an Object Detection a Landmark.
The next step is for AI Trainers to validate the position and azimuth of a Landmark. We validate the output of the AI by visualizing the position and azimuth on a basemap with satellite imagery, by comparing it to Landmarks from other collections, and by examining anomalies in the collection.
In this example of an AI Trainer game, the Map AI positioned the object by using 3D reconstruction to identify the location of the no-U-turn sign relative to the dashcam’s GPS location. The dots on the map at right show the locations where images were captured, and the dashcam icon shows the location of the specific image shown at left.

Once the community of AI Trainers reaches a consensus on the positioning and azimuth of a Landmark, it can progress to the next phase, which is Landmark Merging.
Phase Three: Landmark Merging
Once the Map AI reaches high confidence about positioning and orientation, it can create a Map Feature to represent a distinct real-world object.
To ensure the resulting map is accurate and useful, the Map AI must consistently avoid creating duplicate Map Features for the same real-world object every time a contributor passes by. It must also be able to detect changes such as an object disappearing or its attributes changing. More naive approaches to object detection that do not account for these factors will not be able to generate useful map data.
For the next stage in the Map AI pipeline, landmarks with the same classification, positioning and orientation are automatically conflated into a single Map Feature.
Most of the time, the Map AI merges Landmarks automatically. When the Map AI is less confident, it shows the landmarks to an AI Trainer, who can decide whether they are the same Map Feature.

In the example above, two contributors drove through the same intersection from different directions on different days. Both dashcams captured a no-U-turn sign. Despite the different vantage points, the Map AI correctly recommended merging them into a single Map Feature.
This was enabled by 3D reconstruction, which can distinguish objects based on their positioning and orientation in addition to their GPS coordinates. This approach is critical for addressing situations where multiple distinct Map Features have similar GPS coordinates.
By reviewing the recommendation through an AI Trainer interface, humans help train the Map AI to make those kinds of judgments on its own without human intervention.
Phase Four: Auditing
All right, we’re almost at the finish line!
Once a Map Feature is created, it undergoes a final round of quality audits, including automated checks to detect errors and anomalies. For example, if there are multiple Map Features of the same type in a small area, that may indicate an error in Landmark Merging.
Our system includes a dynamic linting and AI system to give us fine control over what gets reviewed by humans and when. We prioritize the automated auditing of more complex Map Features such as Speed Limits, Turn Restrictions, and Highway Exit signs, where high precision and accuracy is critical.
Since we are constantly detecting objects and generating Landmarks, we can dynamically generate a confidence score for each Map Feature and update it over time.
The image shows a tool called Valve, which is used to visualize and review Map Features. A customer-facing version of this tool is in development to make it easy for data users to explore Hivemapper’s library of Map Features.
We’re incredibly proud of the pipeline we’ve built. But we’re only just getting started.
In the coming months we will be focused on ever-increasing scale and breadth, allowing us to generate Map Features for hundreds of types of map features all around the world. In some cases, when freshness is particularly important (think of an emergency road closure such as the I-95 overpass collapse mentioned earlier in this post) we will prioritize the pipeline to get Map Features added to the map in a matter of minutes.
It’s a long and exciting journey, made possible by AI and humans working together.
Thanks for reading! In the next post in the series, we’ll discuss some of the lessons we learned as we started to build a community around bite-sized AI Trainer tasks.
Share Post





